|
Introdução
Desde a invenção dos primeiros computadores eletrônicos digitais, a quantidade e a complexidade das tarefas sob a responsabilidade destas máquinas vêm aumentando consideravelmente. O que antes era restrito à geração de tabelas de cálculo de trajetórias balísticas, como foi o caso do computador ENIAC durante a 2ª Guerra Mundial, evoluiu para a execução de tarefas bem mais ambiciosas. Métodos computacionais essencialmente exatos e determinísticos passaram a dividir espaço com métodos aproximados e não determinísticos, que estão mais próximos da forma como o ser humano se comporta. Tais métodos, que procuram reproduzir determinadas habilidades dos seres humanos, são comumente denominados “inteligentes” e são amplamente utilizados em reconhecimento de padrões. Um padrão é qualquer entidade da qual é possível extrair algum tipo de característica, seja ela simbólica ou numérica e o que as técnicas computacionais de reconhecimento de padrões buscam, é por uma maneira eficiente de, a partir destas características, organizar estes padrões em agrupamentos ou classes que compartilhem determinadas semelhanças.
Na natureza os padrões se manifestam de diversas maneiras como, por exemplo, sons, formas, imagens, cheiros e sabores e a todo instante os seres humanos, e também outros animais, percebem e interagem com estes padrões com extrema naturalidade. Exemplos disso são as habilidades que o ser humano têm de diferenciar o som do motor de um automóvel do som de uma música dos Rolling Stones, ou ainda, a habilidade que um animal selvagem tem de distinguir uma presa de um predador. A naturalidade inerente a estas habilidades faz com que o ser humano sequer imagine as complexidades cognitivas que estão por trás delas. Complexidades que se tornam evidentes quando se tenta reproduzir as tais habilidades artificialmente em um computador, o que há muito desafia a comunidade científica interessada no assunto.
O reconhecimento de padrões por computador é uma das mais importantes ferramentas usadas no campo da inteligência de máquina. Atualmente está presente em inúmeras áreas do conhecimento e encontra aplicações diretas em visão computacional, análise sísmica, reconhecimento de locutores e de comandos a voz, classificação de sinais de radar, reconhecimento de faces; identificação de digitais, análise e entendimento de sinais eletrocardiográficos, previsão de comportamentos em mercados financeiros, reconhecimento de caracteres impressos e manuscritos, além de outras.
Reconhecimento de Caracteres
Dentre as modalidades de reconhecimento de padrões, o reconhecimento de caracteres é uma das mais conhecidas e exploradas pela comunidade científica. Prova disso é a grande quantidade de artigos publicados anualmente em periódicos e anais de conferências nacionais e internacionais relacionadas, e até mesmo especializadas no assunto. O reconhecimento de caracteres consiste em, a partir de características extraídas de um conjunto de caracteres, separá-los em 10 classes, no caso dos algarismos, ou 26 classes, no caso das letras do alfabeto ocidental.
A busca pelo desenvolvimento de sistemas eficientes para reconhecimento de caracteres é tão antiga quanto o próprio computador eletrônico. Porém, antes deles se tornarem uma realidade, muito desenvolvimento tecnológico foi necessário e o início desta história remonta a 1.870, quando Carey inventou o scanner de retina. Em seguida, em 1.890, Nipkow inventou o scanner seqüencial, que representou um grande avanço tanto para as máquinas leitoras quanto para a televisão moderna. A idéia da criação dos sistemas de reconhecimento de caracteres surgiu da necessidade de auxílio a pessoas portadoras de deficiência visual e a primeira experiência bem sucedida foi realizada pelo cientista russo Tyurin em 1.900.
O marco inicial dos sistemas modernos de reconhecimento de caracteres data de 1.951 quando M. Sheppard, fundador da Intelligent Machine Research Co., criou o GISMO, um que era um sistema leitor-escritor. Posteriormente, em 1.954, um protótipo desenvolvido por J. Rainbow foi utilizado para ler letras maiúsculas datilografadas à velocidade de um caractere por minuto. Somente a partir de 1.967 é que grandes companhias como, IBM, Recognition Equipment, Inc., Farrington, Control Data e Optical Scanning Corporation, começaram a produzir e comercializar estes sistemas.
Os primeiros sistemas comerciais que surgiram foram os chamados sistemas OCR (Optical Character Recognition). Nos OCR’s os caracteres a serem reconhecidos se encontram impressos em uma determinada fonte e, por isso, apresentam um formato bem comportado assim como as letras deste texto. Inicialmente os OCR’s eram capazes de reconhecer apenas tipos específicos de fontes como, OCR-A, OCR-B, Pica, Elite, Courier, etc. Em seguida, surgiram os OCR’s multi-fonte que permitiram que a capacidade de reconhecimento se estendesse para um conjunto maior de opções de fontes. Por fim, surgiram os OCR’s omni-fonte, capazes de reconhecer qualquer fonte.
O passo seguinte foi dado em direção aos sistemas ICR (Intelligent Character Recognition). Diferentemente dos OCR’s, os ICR’s lidam com um problema bem mais complexo, uma vez que os caracteres a serem reconhecidos são manuscritos e não mais impressos. Esta complexidade é devida às variações de estilo existentes na escrita manuscrita, pois de uma pessoa para outra um mesmo caractere pode se apresentar de diferentes formas. Até uma mesma pessoa pode escrever um mesmo caractere de maneiras diferentes. A escrita manuscrita pode ainda se apresentar de duas formas, isolada e cursiva, sendo que no primeiro caso os caracteres estão dispostos de forma não conectada, enquanto que no segundo estão dispostos de forma completamente irrestrita, ou seja, conectados ou eventualmente desconectados.
Os dados de entrada de um sistema de reconhecimento de caracteres podem ser provenientes da digitalização de um documento, por meio de um scanner, ou provenientes de superfícies de cristal líquido, que capturam os caracteres escritos sobre ela com um bastão que imita uma caneta. Estas duas abordagens compreendem os sistemas de reconhecimento denominados off-line e on-line, respectivamente. No caso on-line, à medida que o traço do caractere é delineado pelo escritor, este é prontamente apresentado ao sistema, enquanto no caso off-line, somente a imagem completa do que foi escrito previamente é apresentada ao sistema. Os OCR’s são essencialmente do tipo off-line, enquanto os ICR’s podem ser de ambos os tipos.
Hoje, ao contrário de quando começaram a ser comercializados, os reconhecedores de caracteres apresentam desempenhos bem melhores, preços mais acessíveis e são facilmente encontrados no mercado. Os OCR’s estão presentes na maioria dos programas de interface dos scanners e os ICR’s do tipo on-line são uma das funcionalidades encontradas nos modernos palm tops. Os ICR’s do tipo off-line estão disponíveis principalmente para o reconhecimento de documentos, em especial formulários. Contudo, todos estes produtos ou são totalmente desenvolvidos fora do Brasil ou utilizam pacotes de soluções importadas para a tarefa do reconhecimento dos caracteres.
O Sistema NeuroTexto
O NeuroTexto é um sistema ICR do tipo off-line cuja tecnologia vem sendo inteiramente desenvolvida no LabIC (Laboratório de Inteligência Computacional) do NCE-UFRJ e sua finalidade é processar formulários de concursos de forma automática e eficiente. O sistema já se encontra em fase de protótipo e apresentando resultados bastante animadores. O NeuroTexto é constituído de várias fases que vão desde a captura e digitalização da imagem do formulário até a crítica do resultado do reconhecimento pelo usuário e geração da base de dados alvo. Cada fase corresponde a um módulo do sistema que compreende funções bem específicas. A estrutura do sistema bem como uma breve explicação de cada módulo são apresentados a seguir.
 |
|
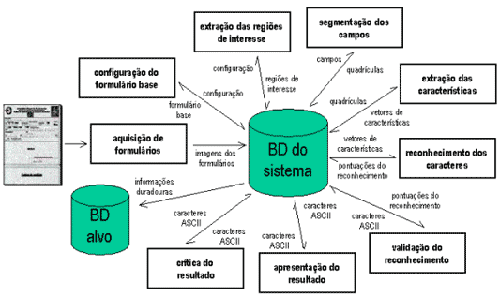
Módulos constituintes do sistema NeuroTexto
|
Aquisição de formulários: é o módulo responsável pela captura do formulário em seu formato físico e o armazenamento de sua imagem em formato digital.
Configuração do formulário base: neste módulo o usuário elege um formulário como sendo a base e define em cima dele as posições das regiões de interesse (campos, marcadores, códigos de barras, assinaturas, etc.), que serão as referências para a extração das regiões de interesse dos outros formulários.
Extração das Regiões de Interesse: a partir das configurações estabelecidas no formulário base, o módulo de extração das regiões de interesse se encarrega de localizar e extrair estas regiões da imagem de cada um dos formulários adquiridos.
Segmentação dos campos: dentre as regiões de interesse extraídas, apenas as que devem ser reconhecidas são endereçadas ao módulo de segmentação, para que se obtenha apenas imagens de caracteres isolados.
Extração das características: é o módulo encarregado de extrair da imagem de cada caractere um conjunto de características numéricas que representam a “assinatura” daquele caractere.
Reconhecimento dos caracteres: recebe como entrada as “assinaturas” dos caracteres e devolve como saída, para cada caractere, um conjunto de 26 valores, se este for uma letra, ou 10 valores, se for um algarismo. Cada um destes valores é interpretado como uma pontuação que associa o caractere à classe correspondente.
Validação do reconhecimento: sua finalidade é dar confiabilidade ao resultado do reconhecimento das letras por meio da aplicação de técnicas de correção de erros, modificando ou confirmando o resultado do reconhecimento de uma letra.
Apresentação do resultado: é o módulo que exibe ao usuário do sistema os resultados do reconhecimento e da validação, para que compare visualmente os resultados com as respectivas imagens dos campos e realize as eventuais correções.
Crítica do resultado: estabelece regras para determinados campos que, quando cumpridas, eliminam inconsistências que se devem, principalmente, a erros de preenchimento cometidos pelos candidatos e não mais a erros cometidos pelo sistema.
Banco de dados do sistema: é responsável pela transferência de informações de um módulo para outro e, ao final de um ciclo de funcionamento do sistema, armazena todas as informações produzidas por cada módulo. Parte destas informações é de interesse do contratante do serviço e é enviada ao banco de dados alvo, enquanto o restante é eliminado.
Banco de dados alvo: armazena as informações que devem ser enviadas ao contratante do serviço, ou seja, as imagens dos formulários, as fotografias dos candidatos, as assinaturas e, evidentemente, os resultados do processo de reconhecimento.
Conclusões
Mesmo com níveis de desempenho considerados satisfatórios, a pesquisa em reconhecimento de caracteres está longe de ser esgotada. Até agora, o sucesso dos sistemas OCR não pôde ser alcançado pelos sistemas ICR, e mesmo os OCR’s ainda apresentam algumas limitações. Limitações estas que estão presentes tanto nas técnicas de tratamento e de extração de informações dos caracteres quanto nas próprias técnicas de reconhecimento. Dentre os sistemas ICR, o bom desempenho está limitado ao reconhecimento de caracteres isolados. Os ICR’s para escrita cursiva, tanto do tipo on-line quanto do tipo off-line, ainda estão longe de apresentar resultados satisfatórios e, por isso, este desafio ainda ocupará as mentes dos entusiastas por um bom tempo.
Clique aqui !!!
|